Bittensor's Templar Subnet Completes First Frontier-Scale Decentralized LLM Training
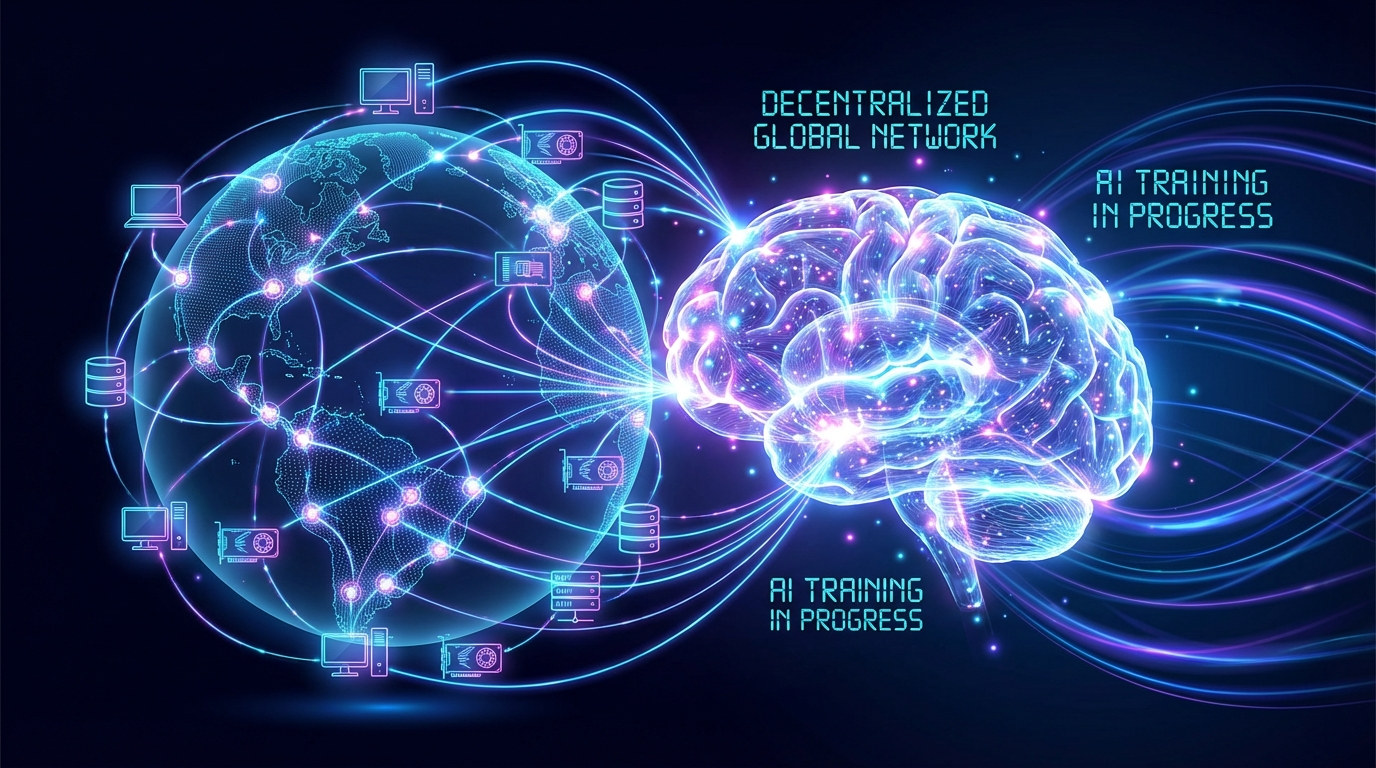
On March 10, 2026, Bittensor Subnet 3 — known as Templar — announced the completion of Covenant-72B, the largest decentralized LLM pre-training run ever completed.
The numbers: 72 billion parameters, approximately 1.1 trillion tokens, trained entirely on commodity internet hardware. No centralized cluster. No whitelisted validators. Anyone with GPUs could join or leave freely throughout the training run.
Why This Matters
Until now, training a frontier-scale language model required hyperscale infrastructure — a data center, a fixed cluster of tightly coupled hardware, and a team of infrastructure engineers to keep it stable. Covenant-72B was trained without any of that.
The Templar team's claim is that the resulting model is performance-competitive with Meta's LLaMA-2-70B, despite being trained permissionlessly across a shifting, voluntary pool of consumer and prosumer hardware over the open internet.
That's a different problem than inference distribution, which has been done before. Distributed training at this scale — coordinating gradient updates, handling node churn, and producing a coherent model — is significantly harder. Prior to Covenant-72B, decentralized LLM pre-training at frontier scale was a roadmap item. Now there's a delivered artifact.
The Bittensor Model
Bittensor works by letting specialized subnets compete for TAO token rewards based on the quality of their outputs. Subnet 3 (Templar) focuses on language model training. Miners contribute compute, validators evaluate the work, and rewards flow accordingly.
The Covenant-72B run demonstrated this can work at scale. The Templar announcement post accumulated 1.7 million views and over 6,000 likes on X, drawing attention from the broader AI and crypto communities.
Mainstream Attention
The achievement gained wider coverage during GTC 2026 week, with investor Chamath Palihapitiya highlighting it on the All-In Podcast as an example of decentralized AI producing results that rival centralized alternatives. TAO saw significant price movement following the announcement, though the more durable signal is what this means for permissionless AI infrastructure.
Templar plans to continue scaling subnet compute and model quality under the Bittensor incentive model.